Query your CloudWatch logs from Athena
Push your logs from Amazon CloudWatch to S3 so that you can query them with Athena.


Amazon Athena provides a powerful mechanism for querying structured data. Amazon CloudWatch Logs are a great way to collect and gather logs from a variety of sources. Is there a way to have the two of them work together?
Not directly. Athena needs to have data in a structured format (JSON, something that can be parsed by a regexp or other formats; more here) with each record separated by a newline. CloudWatch Logs stores the ingested log files in its own data repository not available to Athena. (There are some AWS services which output logs that Athena can directly query.)
There are a couple of ways to make CloudWatch Logs data available for Athena, but first, let’s look at CloudWatch Logs a bit closer.
What is Amazon CloudWatch Logs?
Amazon CloudWatch Logs is a service that acts as a central repository for logging. You can have AWS services or custom applications, like Amazon EC2 instances, AWS CloudTrail, Route 53, or even on premises, and system scripts all push log files into a centralized repository.
There’s also a software agent that is easily installable on Linux and Windows servers that can be configured to monitor one or more log file locations and upload the logs to CloudWatch Logs.
Part of CloudWatch Logs is CloudWatch Logs Insights, which allow you to query JSON logs that contain, via the CLI or a web user interface.
Why would you want to bring log files into Athena?
If CloudWatch Logs provides a querying interface, why would you want to make the log files queryable by Athena? There are a number of reasons:
- Unlike the CloudWatch Logs querying interface, which is non standard, Athena provides a SQL interface. Anyone familiar with SQL can use it.
- Athena provides the ability to do joins across any tables that are backed by S3 or other data sources include those that support JDBC and ODBC. You might want this to correlate events between log files and other data sources.
- Over the long term, especially if you leverage S3 storage tiers, log file storage will be cheaper on S3. According to this 2018 article, with 1TB of logs/month and 90 days of retention, CloudWatch Logs costs six times as much as S3/Firehose.
- Logfiles can be in formats other than JSON and Athena can still query them.
- You can transform the log files on the way to S3 if you need to (enriching the log files by calling out to other APIs, for example).
Why not push logs directly to Amazon S3?
You could, of course, directly push your log files to S3. For a simple application, this may make sense. If you are planning to write an application that already leverages the AWS SDK or API, then adding on one logging call (or more than one) may be easy.
But if you have an existing application that expects to log to a known location on the filesystem, using the CloudWatch agent, which is entirely independent of your application, will be easier than retrofitting AWS API calls into your code.
In addition if you use other AWS services like Lambda which have tight integrations with CloudWatch Logs, it takes no time at all to log to CloudWatch Logs. And it may take substantial work to write to S3.
In the end, if you have a lot of logs already going to CloudWatch Logs but want the advanced querying and integration capabilities of Athena, it makes sense to copy the logs from CloudWatch Logs to S3. With this set up, you will want to set the retention period for the CloudWatch Logs to a very low value to save money.
How to bring CloudWatch Logs to Athena
Before you start
- Create a S3 bucket to which you have write access.
- Make sure you have an IAM account with programmatic and console access and adminstrative privileges. Set up that account in your AWS
~/.credentialsfile. This will be referred to as[profile]below.
Putting logs in CloudWatch Logs
You need to have some logs in CloudWatch Logs before they can be queried by Athena. If you already have this, perhaps from an AWS Lambda function, you can skip the rest of this section, which discusses how to push web server log access log files from an EC2 instance to CloudWatch Logs.
Here is a tutorial which pushes Apache weblogs to CloudWatch. Note that in step 4 you don’t have to rewrite the log files as JSON, so instead add the config line below. Instead we’ll have the standard logs uploaded. Make sure to choose “no” when the wizard prompts you to store the configuration in AWS Systems Manager Parameter Store.
Here’s the relevant Apache config line to add:
CustomLog "/var/log/www/access/access_log" combinedHere’s the relevant CloudWatch agent config:
{
"file_path": "/var/log/www/access/*",
"log_group_name": "apache/access",
"log_stream_name": "{instance_id}"
}Note: If you are following the tutorial, you will not be able to query the logs in CloudWatch Logs Insights (because we aren’t sending the log files as JSON), but you should still be able to see the log group.
Here’s a single line of a sample log file (it’s a standard httpd log file):
111.111.111.111 - - [27/Nov/2019:23:16:36 +0000] "GET / HTTP/1.1" 403 3630 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Safari/605.1.15"Here’s troubleshooting docs for the CloudWatch agent.
Transfer options
Great, so we have some logs in CloudWatch Logs. What are the options for pushing the logs from CloudWatch Logs to S3? You have two alternatives.
The first is to export the CloudWatch Logs. This can be done in the console or in the CLI; to automate this you’d use the latter.
This approach has some advantages. It’s very easy to get started and the log file entries are mostly unchanged (they do have an event timestamp in front of each line that you’ll have to work around, however). Here is an example line; note the first field, starting with 2019-, which is the time that CloudWatch saw the log file line:
2019-11-27T23:16:41.885Z 73.14.174.244 - - [27/Nov/2019:23:16:36 +0000] "GET / HTTP/1.1" 403 3630 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Safari/605.1.15"However, using the export functionality has issues. An export can take up to 12 hours before logs that are visible in CloudWatch Logs are available for export to S3 (based on testing, I saw it take approximately 15 minutes). You can only have one export task running at a time per account, and you will have to deal with de-duping records unless you’re careful about how and when you export. In my opinion, the time lag is the biggest issue. This option is a good fit if you are trying to export logs to S3 for long term storage because of retention costs. For near real time analysis, we’ll need to find another solution.
Using Kinesis Firehose to push log messages in real time from Cloudwatch Logs to S3 is another option. These can then be pushed to any Kinesis Firehose destination (S3, RedShift, ElasticSearch, Splunk). For pushing from CloudWatch Logs to S3, you want to follow the docs here for initial setup (I used the us-west-2 region. If you have high throughput needs, make sure you pick the appropriate region, as some have lower limits).
I created a Kinesis Firehose delivery called cwlogsdelivery, which I’ll reference further on.
We want to make a few tweaks to this default setup. For all these changes we’ll need the destinationId and the current version of the stream configuruation. This command gives us the destinationId (a sample value is "destinationId-000000000001"):
aws --region us-west-2 --profile [profile] firehose describe-delivery-stream --delivery-stream-name cwlogsdelivery --query DeliveryStreamDescription.Destinations[0].DestinationIdUse this value below where you see [destinationid]. We get the current version. Each time we change a configuration, the version will be incremented, so you’ll need to run this each time. This command returns the version ("5"):
aws --region us-west-2 --profile [profile] firehose describe-delivery-stream --delivery-stream-name cwlogsdelivery --query DeliveryStreamDescription.VersionIdUse this value below where you see [versionid]. Note again that this will change each time.
Now, let’s set up a custom S3 prefix to create a key structure such that the resulting Athena table will be partitioned. This will reduce Athena costs and increase query speed, as many types of queries against our weblogs will be limited to a certain year, month or day. (If we wanted to partition on something more specific like the website hostname, we’d need to do some post processing of the logs in S3 either via a Transposit operation or Lambda function.)
The prefix I used was forathena/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/ which partitions by year, month and day. You can also partition by smaller units of time. This command sets the prefix:
aws --region us-west-2 --profile [profilename] firehose update-destination --current-delivery-stream-version-id [versionid] --delivery-stream-name cwlogsdelivery --destination-id [destinationid] --extended-s3-destination-update '{ "Prefix" : "forathena/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/" }'We want to update the buffer settings from their defaults to the minimum values, so we have the lowest latency possible. To update the buffer settings:
aws --region us-west-2 --profile [profile] firehose update-destination --current-delivery-stream-version-id [versionid] --delivery-stream-name cwlogsdelivery --destination-id [destinationid] --extended-s3-destination-update '{ "BufferingHints": { "SizeInMBs": 1, "IntervalInSeconds": 60 } }'Then, we want to modify the format of the records. Unfortunately the records firehose delivers look like this:
{"messageType":"CONTROL_MESSAGE","owner":"CloudwatchLogs","logGroup":"","logStream":"","subscriptionFilters":[],"logEvents":[{"id":"","timestamp":1575931019735,"message":"CWL CONTROL MESSAGE: Checking health of destination Firehose."}]}{"messageType":"DATA_MESSAGE","owner":"11111111111","logGroup":"apache/access","logStream":"i-11111111111","subscriptionFilters":["all-access-logs"],"logEvents":[{"id":"35144436304013166422149585362215604071006564657415389184","timestamp":1575931027916,"message":"111.111.111.111 - - [09/Dec/2019:22:37:07 +0000] \"GET / HTTP/1.1\" 403 3630 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:70.0) Gecko/20100101 Firefox/70.0\""}]}{"messageType":"DATA_MESSAGE","owner":"11111111111","logGroup":"apache/access","logStream":"i-11111111111","subscriptionFilters":["all-access-logs"],"logEvents":[{"id":"35144436309588352721782241158093239858039792077150814208","timestamp":1575931028166,"message":"111.111.111.111 - - [09/Dec/2019:22:37:07 +0000] \"GET /icons/apache_pb2.gif HTTP/1.1\" 200 4234 \"http://ec2-54-185-105-196.us-west-2.compute.amazonaws.com/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:70.0) Gecko/20100101 Firefox/70.0\""},{"id":"35144436320761026066246083352002634712636621191647002625","timestamp":1575931028667,"message":"111.111.111.111 - - [09/Dec/2019:22:37:07 +0000] \"GET /favicon.ico HTTP/1.1\" 404 196 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:70.0) Gecko/20100101 Firefox/70.0\""}]}This message has a number of issues. There is no separator between records and Athena needs newlines. There’s extra metadata (message type, log group) beyond the log line, which is what we really care about.
Luckily, we can process each kinesis firehose message with a lambda. and there’s a default lambda blueprint (named kinesis-firehose-cloudwatch-logs-processor) which extracts the message key. It also separates each message with a newline, which is what Athena wants. Here’s instructions on how to install the blueprint. Note that this will also require you to increase the lambda function’s timeout and add several additional permissions to the firehose service’s IAM role so that it can invoke the lambda. All these can easily be done in the console.
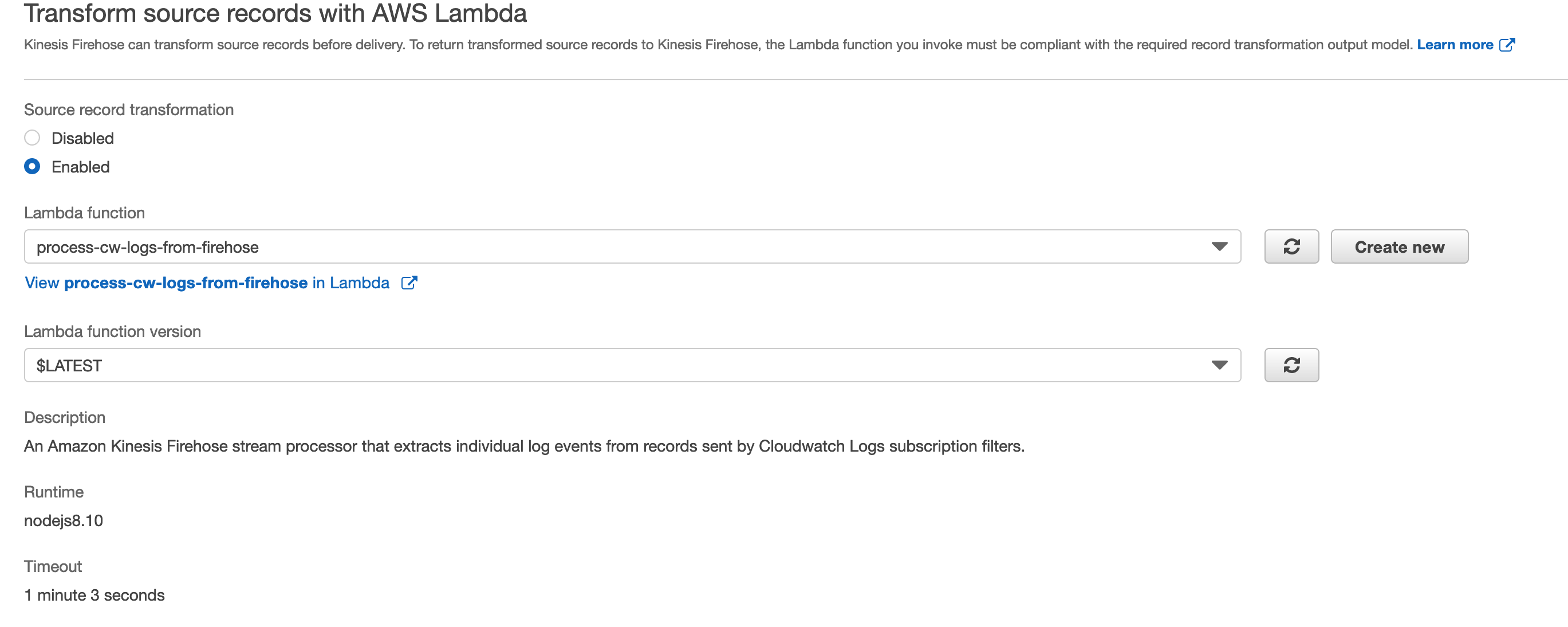
Here’s the relevant section of the Lambda blueprint code, which you would customize if you wanted to do any further enrichment of the CloudWatch Logs output:
function transformLogEvent(logEvent) {
return Promise.resolve(`${logEvent.message}\n`);
}After this is set up, you should be getting properly formatted log records on S3. Go ahead and trigger log files to CloudWatch Log (if you’re following along with the example, that would be just hitting the web server you configured above). Within aboug 75 seconds you should see files delivered to your S3 Bucket which will contain just lines like the original web server line:
111.111.111.111 - - [09/Dec/2019:23:30:57 +0000] "GET /icons/apache_pb2.gif HTTP/1.1" 304 - "http://ec2-54-185-105-196.us-west-2.compute.amazonaws.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:70.0) Gecko/20100101 Firefox/70.0"Querying the log files in S3 with Athena
Finally, we need to set up Athena to query the logs in S3. Below is the DDL for our weblogs in the S3 bucket. We use RegexSerDe (which could also be used against other types of non delimited or complex log files) to split apart the various components of the log line. I found this site useful for testing my regexp against my log lines.
Below, [bucketname] is the name of the S3 bucket that you created and that the log files are sent to by the firehose, and [prefix] is the part of the S3 prefix you specified before the year= section (forathena above).
CREATE EXTERNAL TABLE `cloudwatch_logs_from_fh`(
`ipaddress` string,
`rfc1413id` string,
`userid` string,
`datetime` string,
`method` string,
`filename` string,
`protocol` string,
`status` int,
`size` int,
`referer` string,
`useragent` string)
PARTITIONED BY (
`year` string,
`month` string,
`day` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+\\[(.*?)\\]\\s+\\\"([^ ]*) ([^ ]*) (- |[^ ]*)\\\"\\s+(-|[0-9]*)\\s+([^ ]+)\\s+([^ ]+)\\s+(\\\"[^\\\"]*\\\")')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://[bucketname]/[prefix]'
TBLPROPERTIES (
'has_encrypted_data'='false',
'transient_lastDdlTime'='1575997661')After you create the table, let Athena know about the partitions by running a follow on query: MSCK REPAIR TABLE cloudwatch_logs_from_fh. Then you can run some queries!
SELECT *
FROM cloudwatch_logs_from_fh
WHERE year = '2019' and month = '12'
LIMIT 1Note, the only components which care about the structure of the log files are the process which writes the log files and the Athena DDL. Everything else doesn’t really care, it’s just shuffling messages around. This is a true ELT process, and Athena gives us schema on read.
Let’s talk about latency
Kinesis firehose batches up records according to your settings (both in terms of time and size) and only forwards messages when minimum thresholds are met. From the docs, the minimum thresholds for S3 are 60 seconds or 1MB (whenever either of these are hit, the message is sent).
There’s also the question of how often items are being sent to Cloudwatch Logs (that is, the metrics_collection_interval. The minimum resolution is 1 second, which will impact system cost. Per the CloudWatch docs, “The subscription filter immediately starts the flow of real-time log data from the chosen log group to your Amazon Kinesis Data Firehose delivery stream”.
I ran a couple of tests to get a feel for the latency. Note that I didn’t tweak the metrics_collection_interval from its default value of 60 seconds. A test from web server request (first timestamp) to delivery to S3 (second timestamp) was on the order of one minute when requesting manually:
10/Dec/2019:18:46:36 -> Dec 10, 2019 11:47:57 AM GMT-0700 I also saw latency less than 60 seconds when I used a load testing tool (apachebench) and hit the 1MB buffer limit.
10/Dec/2019:19:22:19 -> Dec 10, 2019 12:22:41 PM GMT-0700 Sample Athena queries
The queries you can run against the CloudWatch Logs log files within Athena depend on the type of data that the log files contain.
For weblogs such as in this example, we could look at the type of request by status code, the number of requests or bytes per time period, the number of server errors, the number of times a specific page was requested over time. Here’s an example query to run in Athena to see what kind of requests your web server is seeing:
SELECT status, count(*)
FROM cloudwatch_logs_from_fh
WHERE year = '2019' and month = '12'
GROUP BY statusConclusion
Hopefully this post gave you some idea how to pull logs that have been ingested by CloudWatch Logs into a format and location that is compatible with Athena. Depending on your needs, either solution may work, but Kinesis Firehose is the more flexible option, even if it is more complex to set up.
Learn how Transposit can help you get contextualized alerts with CloudWatch.



